Comino Mobile Data Center — turnkey liquid-cooled AI infrastructure
From a single rack module to a full 40ft container — same liquid cooling architecture, scaled to your needs

Single-rack module with integrated cooling. No special infrastructure needed — just power connection.
Ideal for: PoC, first AI deployment, edge sites, no infrastructure available

Mid-size container with drycooler on top. Self-contained unit for campus deployments.
Ideal for: Corporate AI clusters, research labs, mid-size deployments
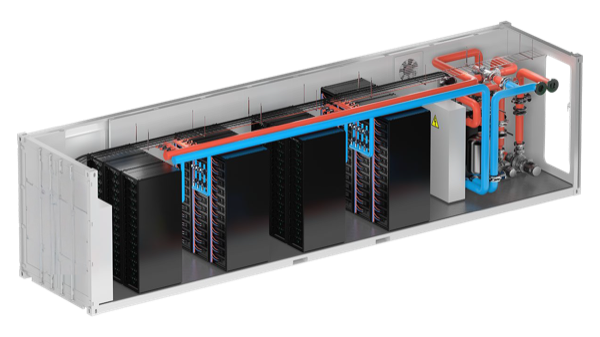
Full-size container with remote drycoolers. Production-grade AI/HPC facility.
Ideal for: Large enterprise, HPC centers, major installations
Deploy at corporate sites or remote locations
Also: Fine-tuning and other AI workloads
Option to reuse waste heat for building heating via plate heat-exchanger. Direct liquid cooling enables PUE below 1.1 — significantly more efficient than traditional air-cooled facilities.
Start with your workload and site constraints. Micro DC (S) is ideal for first deployments, PoC, or sites with no existing infrastructure. Small container (M) works well for mid-size corporate clusters. Full 40ft (L) is for large-scale enterprise AI/HPC.
Comino acts as your main contractor. We coordinate compute, cooling and engineering partners under a single SLA, so you always have one point of contact for uptime, service and warranty questions.
We support the full range of NVIDIA accelerators: RTX Pro 6000 for inference workloads, H200 for current-gen AI, and the latest Blackwell generation — B200, B300, and GB300 NVL. We also work with other GPU platforms on request.
Yes — we are already accepting orders. Lead time starts from 3 months depending on configuration and GPU availability. Contact us to discuss your timeline and lock in a production slot.
Traditional data center builds take 12–18 months from planning to go-live. In AI, that delay means competitors ship products while you're still waiting for infrastructure. Our containerized approach compresses that timeline dramatically — you can deploy production AI capacity in months, not years.
You contact Comino. We triage, dispatch and resolve — whether it's a compute issue, cooling question or container infrastructure. SLA defines response times and escalation paths. One point of contact for everything.
Yes. We offer optional plate heat-exchanger integration that allows waste heat from GPU cooling to be directed into building heating circuits. This improves overall energy efficiency and reduces operating costs.
Tell us about your workload and site — we'll recommend the right size and configuration.
Request Project Call →