New
Desktop form factor DGX Spark
NVIDIA DGX Spark — data center class AI at your desk
A compact personal AI supercomputer powered by the NVIDIA Grace Blackwell architecture — your gateway to the Comino AI ecosystem.
Up to 1 petaFLOP of AI performance (FP4)
128 GB unified system memory
ConnectX‑7 Smart NIC, 10 GbE, Wi‑Fi 7
Scales to Comino Grando when you need more power
AI performance
Up to 1000 AI TOPS
Memory
128 GB LPDDR5x
Form factor
150 × 150 × 50.5 mm
Suitable for working with models of approximately up to 200 billion parameters locally, with an option to scale to around 405 billion parameters by connecting two systems.
DGX Spark
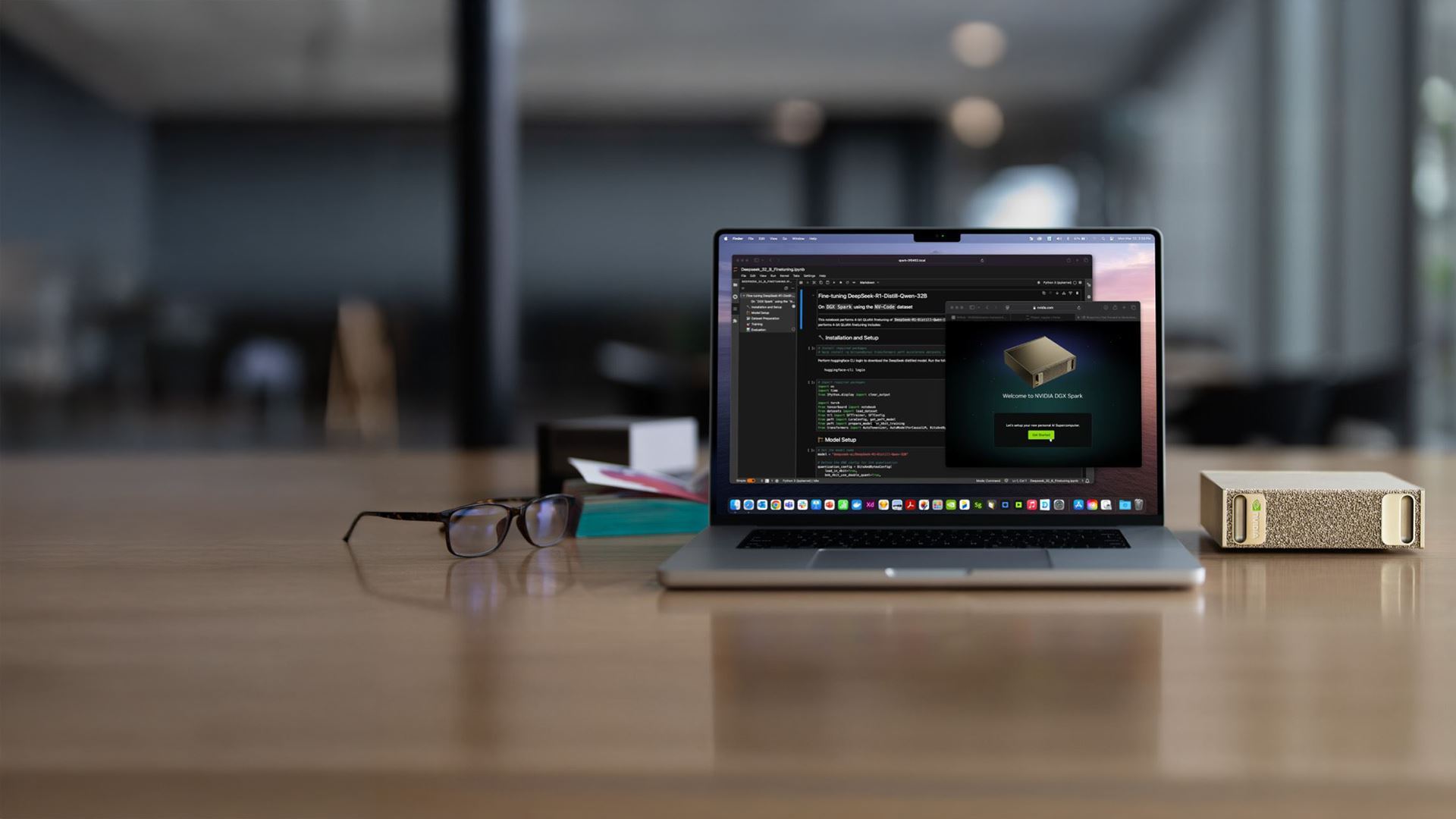
GB10 Superchip with NVIDIA Grace Blackwell architecture
4 TB NVMe M.2 with self‑encrypting storage
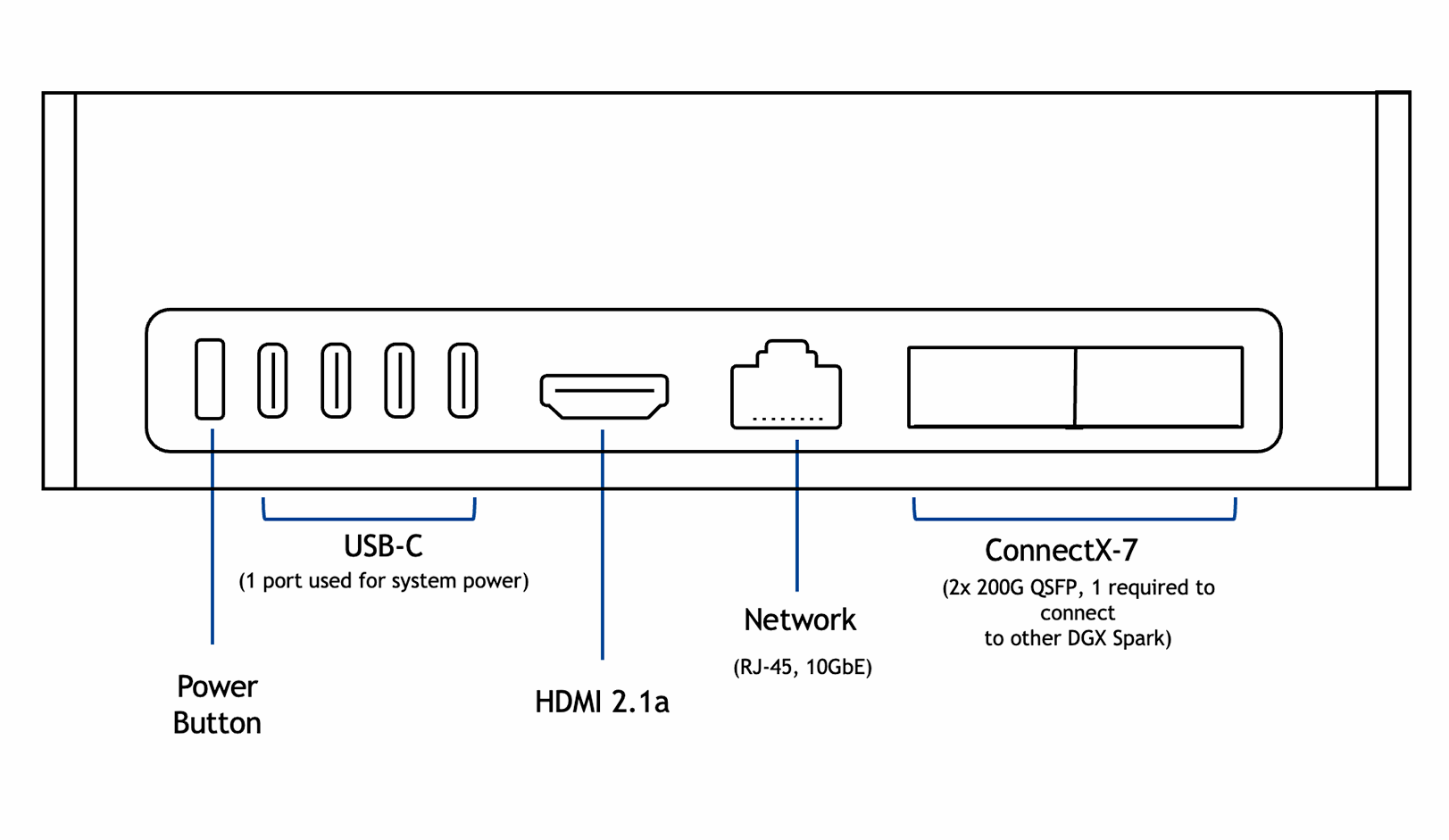
4× USB Type‑C, HDMI 2.1a, 10 GbE
.png)

.webp)
.jpeg)